Topic Extraction Using Non-Negative Matrix Factorization
As part of my exploration into emerging research trends in machine learning, I recently revived an older project of mine. The core idea was simple: gather abstracts from top machine learning journals, process them, and use Non-Negative Matrix Factorization (NMF) to uncover overarching themes in the field.
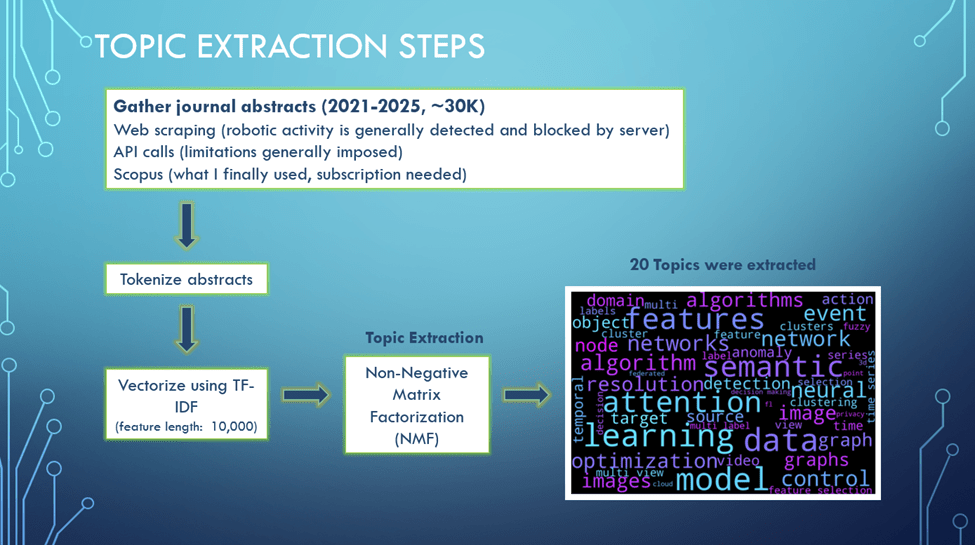
The pipeline looks like this:
Collect abstracts from leading journals.
Preprocess text with tokenization and TF-IDF vectorization.
Apply NMF to extract latent topic clusters.
Analyze results by tracking popularity over time and identifying representative/cited papers for each theme.
Figure 1 End-to-end workflow for topic extraction using NMF: from journal abstract collection to clustering and trend analysis.
Why NMF?
Unlike hard clustering approaches, NMF represents each document as a weighted combination of topics. This fits research papers well, since most span multiple themes (e.g., a paper on attention mechanisms may also touch on optimization strategies).
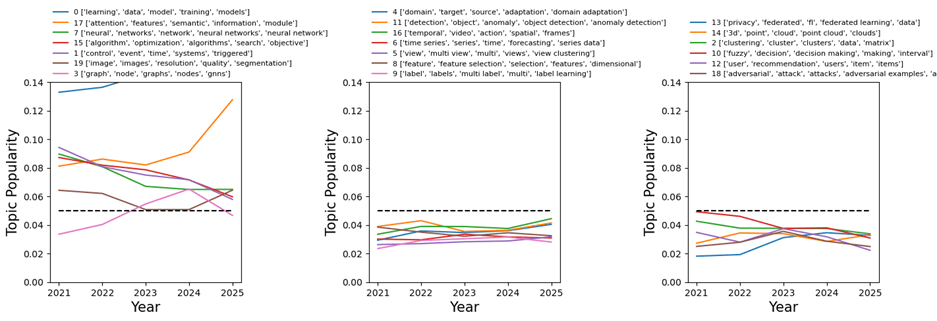
The output not only highlighted well-established areas but also surfaced several emerging fields that were new to me – making this a strong starting point for deeper exploration.
Figure 2 Popularity trends of extracted topics across time, highlighting emerging research themes.
Key Groups and Themes
1. Broad, Foundational Topics
The first four clusters capture the backbone of the ML research landscape:
Particularly relevant is the expansion of transformer architectures into computer vision.
“Transformer, first applied to the field of natural language processing, is a type of deep neural network mainly based on the self-attention mechanism. Thanks to its strong representation capabilities, researchers are looking at ways to apply transformer to computer vision tasks… Given its high performance and less need for vision-specific inductive bias, transformer is receiving more and more attention from the computer vision community.” – 10.1109/TPAMI.2022.3152247
“… feedback optimized control design for a class of strict-feedback nonlinear systems that contain unknown internal dynamics and states that are immeasurable and constrained within some predefined compact sets.” (example: a quarter-car active suspension)
This was the most active industry-driven topic, with contributions from Microsoft, Google, and Snapchat.
“Single-image super-resolution is the process of generating a high-resolution image that is consistent with an input low-resolution image. It falls under the broad family of image-to-image translation tasks, including colorization, in-painting, and de-blurring”
“Diffusion-based image generators have seen widespread commercial interest, such as Stable Diffusion and DALL-E. These models typically combine diffusion models with other models, such as text-encoders and cross-attention modules to allow text-conditioned generation.”
“Deep learning has revolutionized many machine learning tasks in recent years… The data in these tasks are typically represented in the Euclidean space. However, there is an increasing number of applications where data are generated from non-Euclidean domains and are represented as graphs with complex relationships and interdependency between objects. The complexity of graph data has imposed significant challenges on existing machine learning algorithms. Recently, many studies on extending deep learning approaches for graph data have emerged”
Keywords: domain adaptation, cross-domain, transfer
“If an image classifier was trained on photo images, would it work on sketch images? What if a car detector trained using urban images is tested in rural environments?… Generalization to out-of-distribution (OOD) data is a capability natural to humans yet challenging for machines to reproduce. This is because most learning algorithms strongly rely on the i.i.d. assumption on source/target data, which is often violated in practice due to domain shift. Domain generalization (DG) aims to achieve OOD generalization by using only source data for model learning.”
“Small Object Detection (SOD), as a sub-field of generic object detection, which concentrates on detecting those objects with small size, is of great theoretical and practical significance in various scenarios such as surveillance, drone scene analysis, pedestrian detection, traffic sign detection in autonomous driving, etc. There remains a huge performance gap in detecting small and normal-sized objects even for leading detectors.”
7. Predictive Learning of Spatiotemporal Sequences
Keywords: temporal, video, motion, frames
“As a key application of predictive learning, generating future frames from historical consecutive frames has received growing interest in machine learning and computer vision communities. It benefits many practical applications and downstream tasks, such as the precipitation forecasting, traffic flow prediction, physical scene understanding, early activity recognition, deep reinforcement learning, and the vision-based model predictive control. Many of these existing approaches suggested leveraging RNNs with stacked LSTM units to capture the temporal dependencies of spatiotemporal data.”
“Modern cyberphysical systems (CPS), such as those encountered in manufacturing, aircraft and servers, involve sophisticated equipment that records multivariate time-series (MVTS) data from 10s, 100s, or even thousands of sensors. The MVTS need to be continuously monitored to ensure smooth operation and prevent expensive failures”
This project demonstrates how topic modeling can map the evolving landscape of machine learning research. By systematically analyzing abstracts, we can:
Track emerging vs. declining research themes
Identify seminal works within each cluster
Spot areas ripe for exploration and collaboration
For me, the most exciting part was uncovering entire research areas I hadn’t explored before – a reminder of just how fast the field continues to expand.
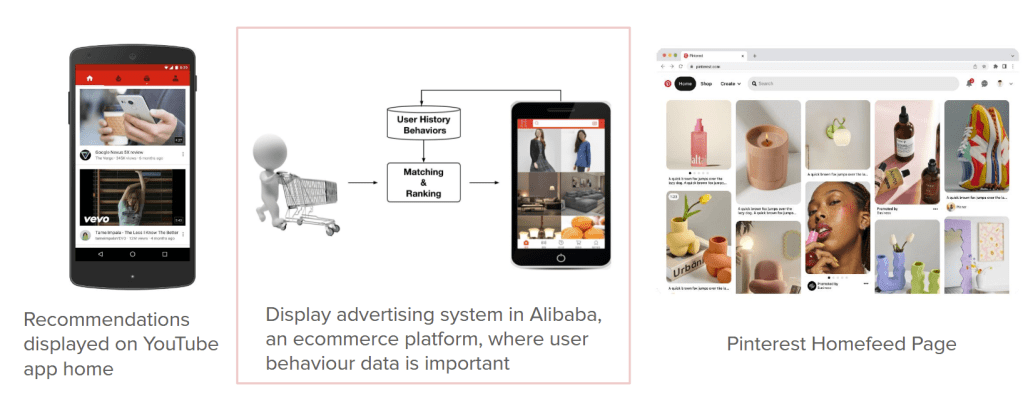
In my work measuring digital advertising campaigns, I often see how quickly the landscape shifts—driven by advances in transformers and deep learning. These changes make it important to pause and assess which innovations are most relevant to improving outcomes for advertisers and platforms. The Deep Interest Network (DIN) paper caught my attention as a practical and meaningful contribution. Using it as a starting point, I explored the key developments that led here, considered where DIN fits into the broader CTR prediction landscape, and reflected on possible directions for future progress.
Click-through rate (CTR) prediction is the lifeblood of modern digital advertising and recommendation systems. Whether it’s deciding which product to show on Amazon, which video to recommend on YouTube, or which ad wins in a real-time bidding (RTB) auction, CTR estimates directly affect both user experience and revenue.
While CTR prediction has been studied for years, the Deep Interest Network (DIN)—introduced by Alibaba Group researchers—brings a fresh perspective to a long-standing challenge: how to model diverse and context-dependent user interests effectively.
Why CTR Prediction Is Hard
CTR prediction systems face three major challenges:
Extreme Sparsity in Data Most user and item attributes are categorical and extremely sparse. In datasets like Criteo’s, the feature space can have tens of millions of dimensions with >99.99% sparsity. Simple models like logistic regression struggle to generalize in such conditions.
Complex Feature Interactions User behavior patterns often depend on high-order interactions—e.g., {Gender=Male, Age=10, ProductCategory=VideoGame}—which can’t be captured by looking at features in isolation. Manually engineering these interactions is labor-intensive and incomplete.
Context Dependence of User Interests A single user’s browsing history may span multiple categories (e.g., handbags, jackets, electronics). Not all interests are equally relevant to every ad impression.
Modeling Approaches
From Embeddings to Interest Modeling
The first step in modern CTR models is to convert high-dimensional categorical features into dense, low-dimensional embeddings—similar to how NLP models embed words. This reduces dimensionality and captures latent structure (e.g., product category similarity). In standard models, these embeddings are pooled (often averaged) into a single user vector and fed into a prediction network. While effective, this approach compresses all user interests into one fixed-length vector, losing granularity.
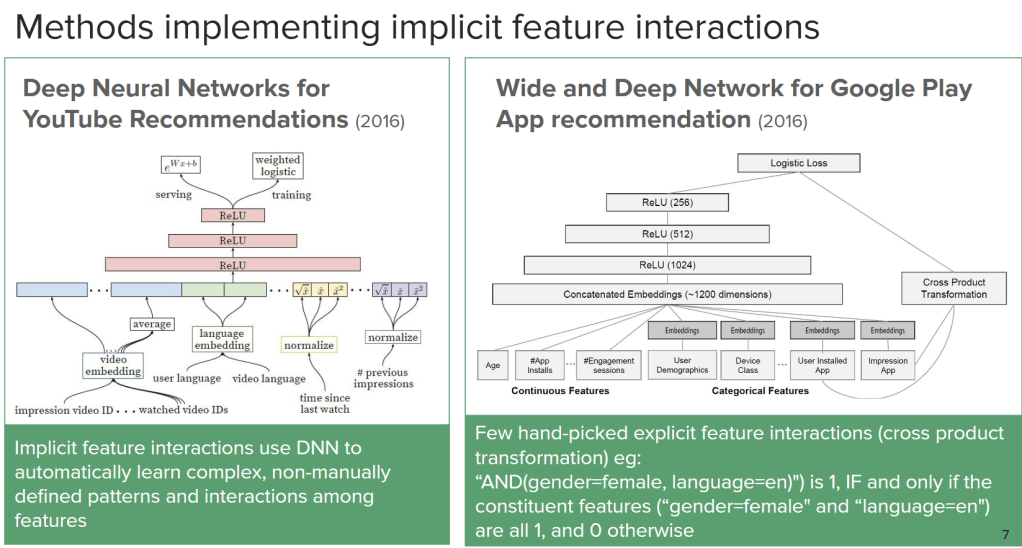
Implicit vs. Explicit Feature Interaction Approaches
Industry research has pursued two main paths:
Implicit Interaction Models – Let deep neural networks discover feature interactions automatically. Examples:
Wide & Deep (Google Play)
YouTube’s recommendation DNN
Explicit Interaction Models – Model and expose feature interactions explicitly for interpretability. Examples:
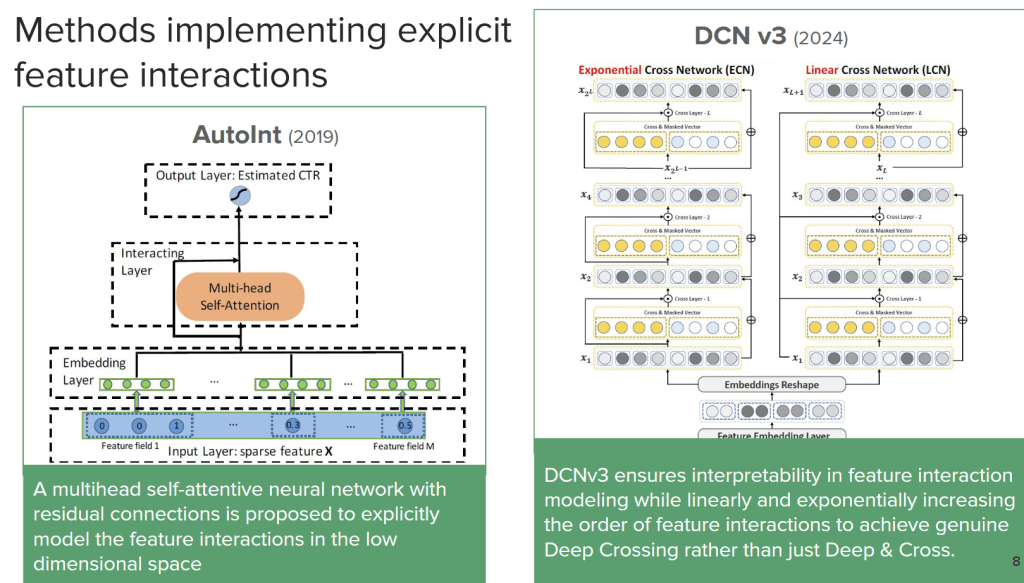
AutoInt (multi-head self-attention for feature interaction)
DCNv3 (deep cross networks with interpretable crossing layers)
Deep Interest Network
Limitations of Fully Connected Implicit Interaction Models
Fully connected implicit interaction models can only handle fixed-length inputs. Diverse interests of the user are compressed into a fixed-length vector (of manageable size), which limits model expressive ability. It is also not necessary to compress all the diverse interests of a certain user into the same vector when predicting a candidate ad because only part of the user’s interests will influence their action (to click or not to click).
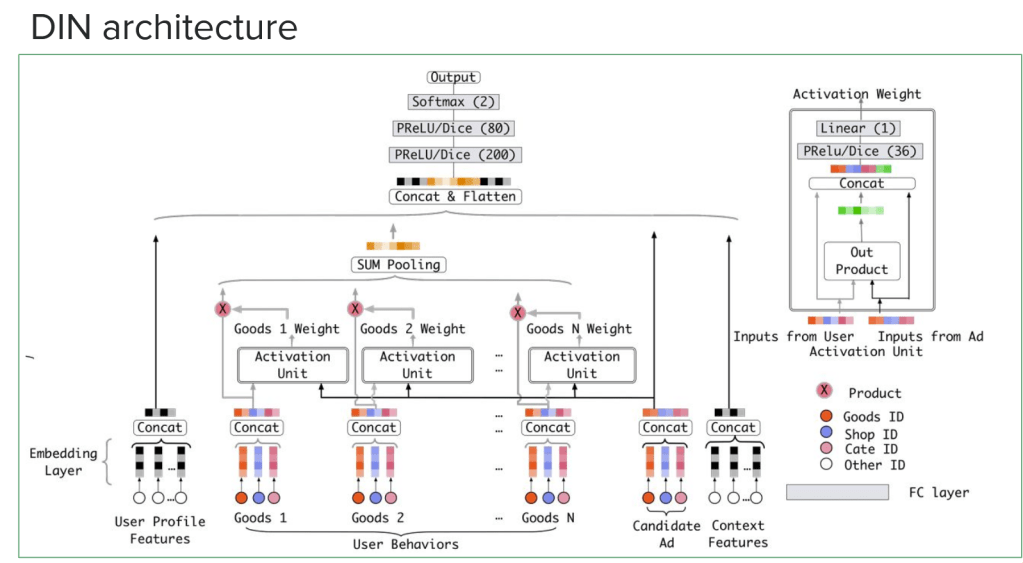
DIN’s Key Innovation: Local Activation Unit
As an implicit interaction model, DIN builds on the approaches discussed above but takes them a step further by directly addressing the context-dependence problem. It does this through a local activation unit, which adaptively weighs a user’s historical behaviors according to their relevance to the current ad.
For a t-shirt ad, clothing-related behaviors get more weight.
For a smartphone ad, electronics-related behaviors dominate.
Unlike traditional attention in transformers, DIN’s activation weights are not normalized, allowing stronger emphasis on dominant interests.
This produces a context-specific user interest vector, enabling the model to focus on the subset of historical interactions most likely to influence the click decision.
Training Techniques That Make It Work at Scale
Alibaba’s production environment involves 60M users and 0.6B products, so efficiency matters.
Mini-batch Aware Regularization – Applies L2 regularization only to features present in the current mini-batch, avoiding unnecessary computation on inactive features.
Dice Activation – A data-adaptive activation function that shifts its rectification threshold based on the input distribution, improving stability across layers.
Results: Tangible Gains at Alibaba
During almost a month’s A/B testing in Alibaba (2017):
+11% weighted AUC compared to the base DNN.
+10% CTR and +3.8% revenue per mille (RPM) in a month-long A/B test.
These gains led to DIN’s deployment across Alibaba’s large-scale display advertising system.
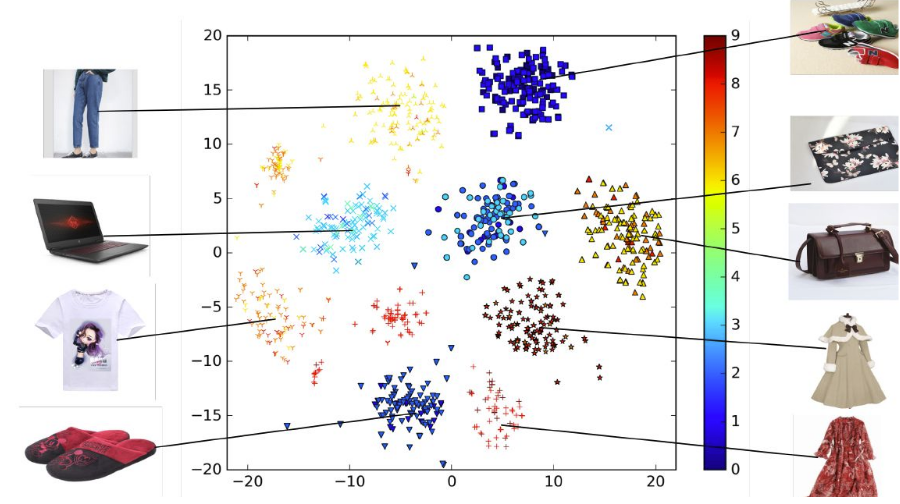
Visualization Insights
A t-SNE visualization of learned embeddings showed (Points with same shape correspond to ads in the same category. Color indicates CTR for each ad.):
Items from the same category naturally clustered together—despite no explicit category supervision.
Click probabilities varied smoothly within these clusters, showing the model’s nuanced interest mapping.
Why DIN Matters
DIN’s contribution goes beyond Alibaba’s needs. It illustrates a broader principle for recommender and ranking systems:
User interests should be modeled in a context-dependent, dynamic way rather than compressed into a single static profile.
From my perspective in digital ad measurement, DIN represents a solid step toward more context-aware personalization. It bridges current best practices with the potential of emerging approaches, hinting at a future where CTR models combine adaptiveness with greater interpretability. As transformer-based architectures and advanced attention mechanisms continue to evolve, I expect DIN’s core ideas to remain central to shaping the next generation of advertising intelligence.y.
References
Zhou et al., Deep Interest Network for Click-Through Rate Prediction, KDD 2018.
Song et al., AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks, 2019.
Wang et al., DCNv3: Towards Next Generation Deep Cross Network for Click-Through Rate Prediction, 2024.
Cheng et al., Wide & Deep Learning for Recommender Systems, 2016
Covington et al., Deep Neural Networks for YouTube Recommendations, 2016
I am passionate about learning the intricacies of data science and disseminating what I learn. This blog is my attempt at making these involved and sometimes complicated concepts more accessible to anyone who is interested 🙂